


Hola de nuevo,
En esta entrada vamos a hablar de la estructura general de ÁTICA y cómo permitir que los robots de los buscadores puedan explorar los contenidos públicos de manera que salgan en sus resultados. Puede resultar chocante esta mezcla de temas, pero todo tendrá sentido en su momento.
Aplicaciones web
Es difícil definir el concepto de aplicación web con exactitud sin usar lenguaje muy técnico, de hecho es un tema que daría para varias entradas. Sin embargo la idea intuitiva es sencilla: es una aplicación que se ejecuta a través de un navegador web, ni más ni menos. ¿Ejemplos? Gmail, Facebook, Séneca (la aplicación de gestión docente de la Consejería de Educación de Andalucía) e incluso cualquier periódico digital actual. En definitiva, cualquier sitio web cuyo contenido no sea estático y, por tanto, sea capaz de reaccionar a las acciones del usuario que accede a ellas.
Algunas de las ventajas de una aplicación web frente a una aplicación de escritorio tradicional son la ubicuidad (mientras haya una red que conecte la aplicación con el usuario), el soporte de varios usuarios simultáneos y, si está bien hecha, la independencia del sistema operativo y navegador usado por el usuario.
Ojo: una aplicación web no implica que los contenidos deben accederse remotamente a través de una red. De hecho, puede instalarse una aplicación web en local y funcionar perfectamente aunque con ello perdemos parte de sus ventajas.
Por supuesto, ÁTICA es una aplicación web.
Arquitectura de una aplicación web
Como es lógico, no todas las aplicaciones web son iguales. La forma que tienen de obtener la información, procesarla y presentarla al usuario varía de unas a otras, al igual que los métodos de interacción del usuario con la aplicación. Dado que en una aplicación web intervienen muchos elementos (un navegador web, uno o varios servidores, bases de datos, etc.) es muy común describir una aplicación indicando qué funcionalidad realiza cada uno de esos elementos. A esa descripción se le denomina arquitectura de una aplicación web.
¿Cuáles son esas funcionalidades? Depende de la fuente consultada, pero el consenso general suele distinguir tres grandes funcionalidades: presentación, lógica de aplicación y almacenamiento.
- Presentación: Es la que permite al usuario elegir qué información necesita, se la muestra y le permite interactuar con ella.
- Lógica de aplicación (o lógica de negocio): Es la encargada de implementar el comportamiento de la aplicación (calcular la suma de una factura, realizar avisos, realizar búsquedas, etc.)
- Almacenamiento: Como su nombre indica es el lugar donde los datos se guardan y son recuperados posteriormente para poder llevar a cabo la lógica de negocio.
Por supuesto, esta clasificación no es única ni aplicable a todos los casos.
En las aplicaciones tradicionales de escritorio, todas las funcionalidades están integradas en la misma entidad: el programa. En una aplicación web (exceptuando las locales) suelen estar repartidas como mínimo en dos elementos: el navegador web y un servidor. A cada uno de esos elementos se les denomina tier y esto nos permite definir varias arquitecturas web dependiendo del número de tiers: 2-tier, 3-tier y, en general, n-tier (cuidado, se ha sacrificado exactitud técnica en las definiciones para facilitar su comprensión).
Pongamos como ejemplo una arquitectura 2-tier, también conocida como cliente/servidor y que es de las más comunes en las aplicaciones web clásicas:
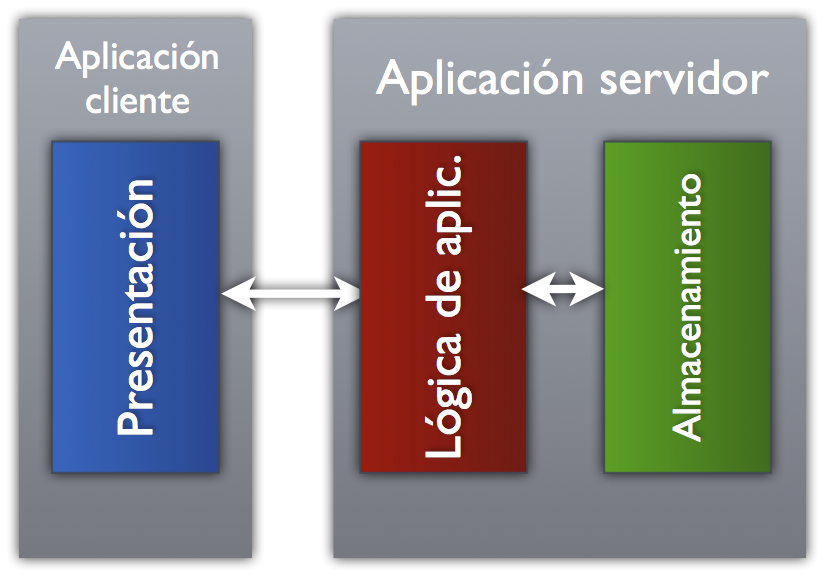
En este caso, el cliente o navegador web (Chrome, Firefox, Internet Explorer, etc.) solamente tiene como responsabilidad mostrar la información que le indique el servidor y de indicar a este último cuando el usuario interactúa con los datos (por ejemplo, pinchando un enlace). Todo el almacenamiento y procesado de los datos se realiza en el servidor, el cliente es meramente una «ventana» dibujada por el navegador.
Cada una de esas funcionalidades estará implementada por una o varias tecnologías. Por ejemplo: lo que el navegador muestra al usuario suele ser una página descrita mediante HTML y CSS en la que se incluye el contenido y cómo debe presentarse. La lógica de aplicación del servidor genera esa información dirigida al navegador mediante algún lenguaje de programación tipo PHP, JSP, Ruby, ASP.net, etc. Los datos que se necesitan para ello se obtienen de algún sistema gestor de bases de datos como Oracle, MySQL, MSSQL, MongoDB, etc.
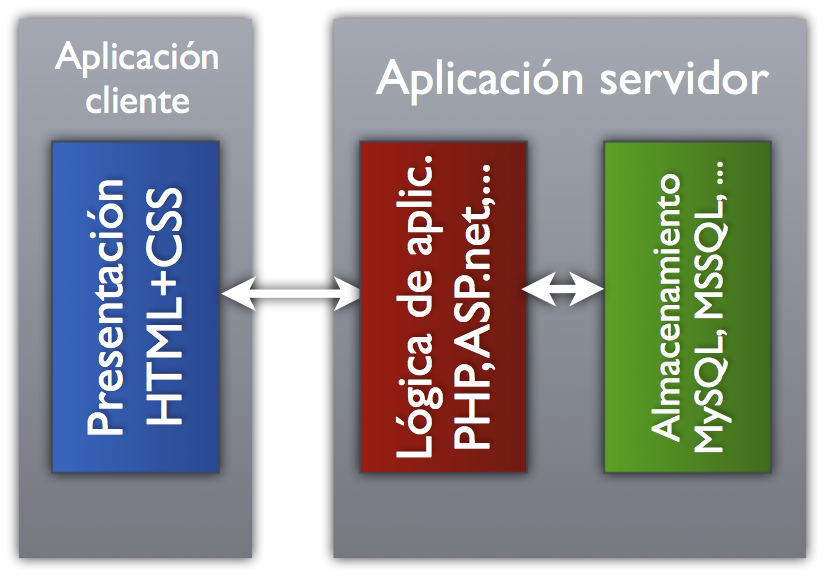
Sin embargo, todos esos detalles quedan ocultos al usuario final, como no puede ser de otra forma.
Un ejemplo de arquitectura 3-tier sería aquella que coloca el almacenamiento en otro servidor distinto de manera que pueda ser accedido por varios elementos de lógica de aplicación simultáneamente. Es la evolución lógica si la demanda de la aplicación aumenta y queremos que el tiempo de respuesta se mantenga rápido.
Por otro lado, últimamente están proliferando las aplicaciones web donde parte o la totalidad de la lógica de aplicación se traslada directamente al navegador. ¿Por qué? Entre otras cosas, descarga al servidor de responsabilidades que el cliente puede realizar sin mucho esfuerzo pues los navegadores actuales son muy capaces a la hora de ejecutar código. Otro de los motivos suele ser que permite reducir la cantidad de información que se envía por la red, pues sólo se solicitan aquellos datos imprescindibles en un momento dado.
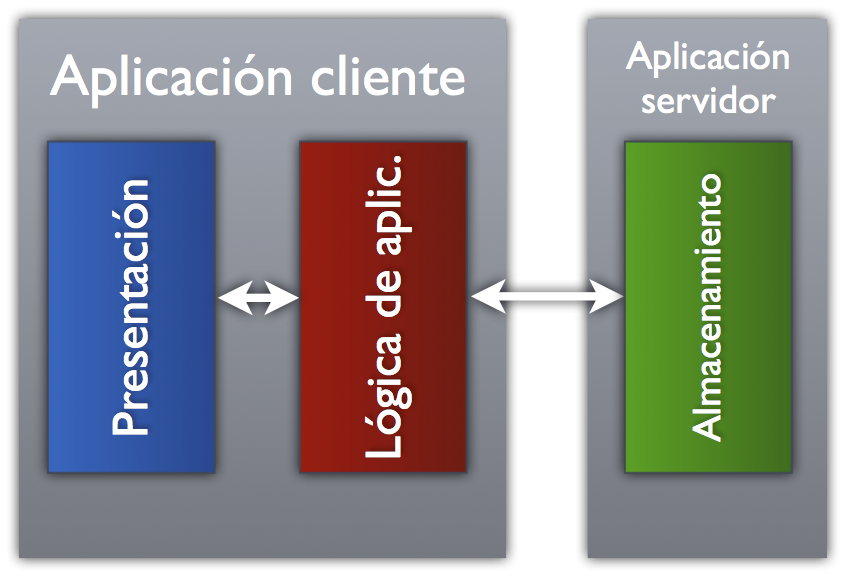
Pongamos un ejemplo sencillo: Imagina una aplicación que permite listar los pedidos realizados. Una aplicación web que tenga la lógica de aplicación en el cliente permitiría solicitar solamente aquellos pedidos que caben en la pantalla e iría pidiendo más silenciosamente conforme el usuario vaya avanzando en la lista. También permitiría realizar operaciones de filtrado con los datos previamente enviados sin tener que solicitarlos de nuevo o podría calcular la suma del importe de los pedidos seleccionados sin molestar al servidor.
En estos casos, el papel del servidor casi se reduce a ser un simple intermediario con la base de datos. Si la aplicación está bien diseñada, esto repercutirá en una mayor capacidad de servicio pues podrá atender más solicitudes con los mismos recursos.
Por supuesto, en la realidad es muy fácil encontrar modelos mixtos que no son estrictamente como los dos ejemplos que hemos descrito sino algo intermedio. Un ejemplo lo tenemos en Séneca, donde la mayoría de la lógica de aplicación se encuentra en los servidores de la Junta pero alguna funcionalidad se ejecuta desde el navegador (por ejemplo, desplegar un menú o seleccionar un conjunto de estudiantes para realizar una operación sobre ellos).
¿Y ÁTICA? La versión actualmente desplegada es casi un 100% similar al primer ejemplo, donde toda la carga recae sobre el servidor. Este modelo ha tenido lógica en tanto el servidor normalmente se encuentra en el mismo centro y tiene una carga baja de usuarios. Pero la nueva versión soportará más de un centro bajo el mismo paraguas, con lo que es posible que el número de operaciones y, consecuentemente, el tráfico aumente.
Todo esto nos lleva a que la próxima revisión de la plataforma trasladará parte de la carga de trabajo al cliente, lo que debería aumentar la velocidad de respuesta aunque el cliente se encuentre lejos del servidor mientras se reduce la carga de trabajo de este último.
Hay muchas formas de implementar la lógica de aplicación en el cliente. Entrando en detalles técnicos, en nuestro caso estamos usando AngularJS y Javascript, de manera que los datos se solicitan al servidor cuando se necesitan mediante una interfaz RESTful.
Aplicaciones en el navegador y los buscadores
No todo es de color de rosa cuando damos trabajo al navegador. Uno de los problemas que originalmente se atribuían a esta arquitectura es el soporte para dispositivos móviles, pues no suelen contar con mucha capacidad de procesamiento o de memoria. Afortunadamente, hoy en día no es el caso. La mayoría de los dispositivos móviles actuales tienen una capacidad razonable y, además, soportan la mayoría de las tecnologías web modernas. De hecho, el mayor inconveniente para usar una aplicación en un dispositivo móvil no suele ser éste, sino las limitaciones del tamaño de la pantalla y de interacción del usuario (un dedo no es tan preciso como un ratón). Por supuesto, también existe una solución para esto: el diseño adaptativo (responsive design), pero eso es materia para otra entrada.
Ya comentamos antes que íbamos a relacionar la arquitectura web con los buscadores, y aquí está el motivo: un buscador descarga páginas web de los servidores y las analiza para indizarlas e incluirlas en sus resultados. Los grandes buscadores suelen realizar esas descargas mediante la utilización de bots o arañas (spiders), que no son más que programas que se bajan páginas, las analizan y descubren nuevos enlaces en ellas que posteriormente son también descargados. Una vez han recibido los contenidos de una página, se incluyen en el índice del buscador. El proceso se repite hasta cubrir la mayor parte de la telaraña de la web.
¿Cuál es el problema entonces? En el caso de las aplicaciones web donde la lógica de aplicación está en el navegador, la página que se descarga del servidor no suele incluir datos sino simplemente un esquema o plantilla que luego se rellena con información obtenida dinámicamente según las acciones del usuario. Tampoco suelen incluir todos los enlaces posibles porque muchos se generan dinámicamente por el propio navegador.
Por tanto, si la aplicación tiene toda la lógica en el navegador, es más que probable que un buscador no pueda tener acceso a la información que nos gustaría que apareciera en los resultados.
Para variar Google ya ha pensado en esto y ha creado una guía para los programadores que, de seguirse, permite que sus robots puedan acceder a información descargada dinámicamente por la aplicación. Resumiendo mucho, lo que hace es avisar al servidor para que éste le envíe «instantáneas» de cada sección de la aplicación en lugar de lo que tiene que ejecutarse en el navegador.
Pero la solución por la que hemos optado es mucho más sencilla. Lo primero es plantearse qué necesitamos que sea analizado por un buscador, y en nuestro caso es solamente la parte pública, es decir, aquellos documentos que el administrador local ha marcado para que se puedan descargar sin que un usuario entre en la aplicación.
Dado que el acceso público es independiente del acceso de usuarios registrados y no es muy complejo de implementar, el nuevo ÁTICA procesará la parte pública completamente en el servidor en lugar de «compartir» la carga con el navegador. ¡Problema solucionado!
Si tenéis dudas o sugerencias, dejad un comentario. ¡Hasta la próxima!
Comentarios recientes